前言:雲端時代的「算力大爆發」與隱形成本
在當前的數位轉型浪潮中,企業技術決策者經常面臨一種雙重焦慮:一方面是面對突發流量(可能是氣象預測、基因組學等高強度運算任務時),擔心既有架構無法負荷;另一方面則是恐懼為了應對峰值而預置的過剩資源,在平時演變成吞噬毛利的閒置成本。
身為資深雲端架構師,我常被問到:「為什麼我們選用了最強大的 EC2 實例,系統效能卻依然無法線性增長?」答案往往不在於硬體規格,而在於「編排(Orchestration)」與「負載平衡(Load Balancing)」的藝術。擁有頂級伺服器僅是起點,如何運用 AWS 的自動化工具駕馭這些資源,才是從「技術債」走向「技術紅利」的關鍵。本文將深入剖析 AWS 在運算與負載平衡領域的技術核心,提煉出足以影響架構成敗的五大策略。
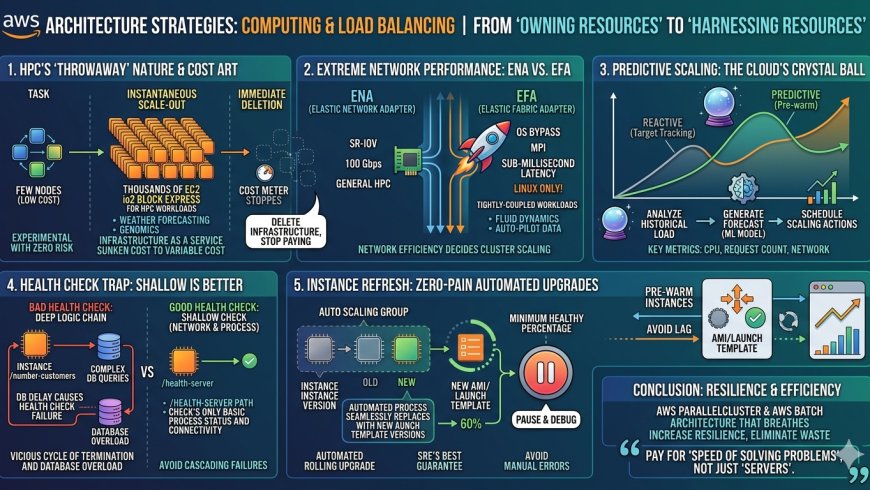
策略一:HPC 的「即用即丟」——高性能運算的成本藝術
傳統高效能運算(HPC)是極度資本密集(CapEx)的投資,往往需要建置昂貴的機房與維護龐大的計算叢集。但在雲端架構中,HPC 的遊戲規則已徹底改寫。對於天氣預報、計算化學、金融風險建模與深度學習等任務,雲端提供了「彈性基礎設施」的終極解法。
雲端執行 HPC 的精髓在於:根據任務量級,在數分鐘內橫向擴展出數以千計的運算節點,待任務結束後立即將其銷毀。這種「實驗無風險、算力即服務」的模式,讓研發團隊能大膽嘗試不同參數,而無需承擔長期折舊。
「一旦完成,我們就可以刪除整個基礎設施,而且不用支付一分錢。」
這種「刪除基礎設施即停止付費」的邏輯,將傳統財務模型中的「沈沒成本」轉化為精確的「變動成本」。配合 io2 Block Express 提供的 256,000 IOPS 極致儲存效能,架構師能以最小的預算達成最大的科學突破。
策略二:極致網路效能的代價——EFA 與 100 Gbps 的門檻
當運算任務涉及大量節點間通訊(Inter-node communication)或緊密耦合的工作負載(如自動駕駛資料處理)時,網路延遲將直接決定叢集的擴展效率。AWS 提供了兩種關鍵的網路方案:
- ENA (Elastic Network Adapter):支援 SR-IOV (Single Root I/O Virtualization) 技術,提供高達 100 Gbps 的頻寬,並顯著提升每秒資料包處理量(PPS),是通用型高效能運算的標準配置。
- EFA (Elastic Fabric Adapter):這是專為頂級 HPC 打造的神經網路介面。EFA 的關鍵在於利用 MPI (Message Passing Interface) 標準,並透過硬體加速技術繞過底層 Linux 作業系統核心(OS Bypass),直接與硬體通訊,實現次毫秒級(Sub-millisecond)的極低延遲。
架構師的戰略選擇: 我必須強調,EFA 僅支援 Linux 作業系統。這是一個強制的技術門檻。如果您在規劃基因組學或大規模流體力學運算時需要 EFA 的極致性能,就必須在作業系統層級採取 Linux 優先策略。一旦網路底層透過 SR-IOV 與 EFA 優化完成,下一步便是思考如何根據負載精準地調整這些優質節點的數量。
策略三:預測性擴展 (Predictive Scaling)——雲端的「水晶球」
多數團隊習慣使用「目標追蹤動態擴展 (Target Tracking Scaling)」,例如設定 CPU 維持在 40%。雖然這能應對一般變動,但其本質是「反應式」的。而對於有規律可循的流量,我們應轉向更具前瞻性的預測性擴展 (Predictive Scaling)。
預測性擴展的運作遵循一套精密的三步流程:
- Analyze historical load:分析過往的負載歷史規律。
- Generate forecast:運用機器學習模型產生未來 48 小時的負載預測圖。
- Schedule scaling actions:自動提前安排擴展行動,確保實例在流量高峰到達前就已完成熱機(Warm-up)。
此外,架構師也應善用 Step Scaling,透過 CloudWatch Alarms 建立更細緻的階梯式擴展邏輯,作為動態與預測之間的緩衝。在設定 Auto Scaling Group (ASG) 時,以下指標是確保穩定性的核心:
- CPU 使用率 (CPUUtilization):基本的算力指標。
- 每個目標的請求數 (Request Count Per Target):確保負載平衡器(ALB)後端的每個實例承載的連接數精確穩定。
- 網路流量:特別針對大資料傳輸或影音串流場景。
策略見四:健康檢查的陷阱——為何「淺層檢查」優於「深層邏輯」
在 ASG 中,健康檢查(Health Check)是系統自癒的核心。但許多開發者常掉進「深層檢查(Deep Health Check)」的陷阱。
- 不良的健康檢查 (Bad Health Check):例如將健康指標指向一個會執行資料庫查詢的 API 路徑(如
/number-customers)。一旦後端 RDS 發生短暫延遲或連線數滿載,本來運作正常的 EC2 實例會因為無法及時回傳資料庫結果而被判定為「不健康」。 - 連鎖反應: 此時,**ASG 會發瘋(Go crazy)**地終止這些其實健康的實例並嘗試重建,這不僅增加了資料庫的冷啟動負載,更可能導致整個服務陷入不斷重啟的死循環。
專家建議: 健康檢查應採取「淺層檢查(Shallow Check)」原則。建立一個專用的 /health-server 路徑,僅用於確認網路可達性與應用程式進程狀態。健康檢查的目的是確認「該實例是否能處理請求」,而非「整個業務供應鏈是否完美」。
策略五:Instance Refresh——零痛感的自動化滾動升級
過去,更新 AMI 或啟動範本(Launch Template)往往伴隨著手動終止實例的風險,或需要複雜的 CloudFormation 滾動更新配置。AWS 的 Instance Refresh 為維運團隊帶來了真正的「平靜」。
這項功能透過設定「最小健康百分比」(例如 60%)來自動執行更新。ASG 會有意識地逐一終止舊版本實例,並根據新的啟動範本建立新實例,同時嚴格確保線上服務實例不低於設定的健康比例。
對 SRE 人員來說,最強大的保障在於:Instance Refresh 的所有過程都是可以隨時暫停(Pause)的。如果在更新過程中發現新版本 AMI 存在異常,您可以立即中止更新並進行除錯。這種自動化編排替代了高風險的人手操作,實現了真正的無痛升級。
總結:從「擁有資源」到「駕馭資源」的思維轉變
在現代雲端架構中,「擁有」多少伺服器已不再是技術實力的象徵,如何「駕馭」資源才是分水嶺。透過 AWS ParallelCluster 快速部署 HPC 叢集,或利用 AWS Batch 自動化編排跨多個實例的批次作業,我們正處於一個「算力按需分配」的黃金時代。
優質的架構應該像呼吸一樣,隨著業務節奏收縮擴張。從 EFA 的網路優化、預測性擴展的超前部署,到 Instance Refresh 的自動更新,這一切的背後都是為了同一個目標:提升韌性並消除浪費。
最後,請審視您的架構圖並捫心自問:「在您的帳單裡,您是在為『伺服器』付費,還是在為『解決問題的速度』付費?」





