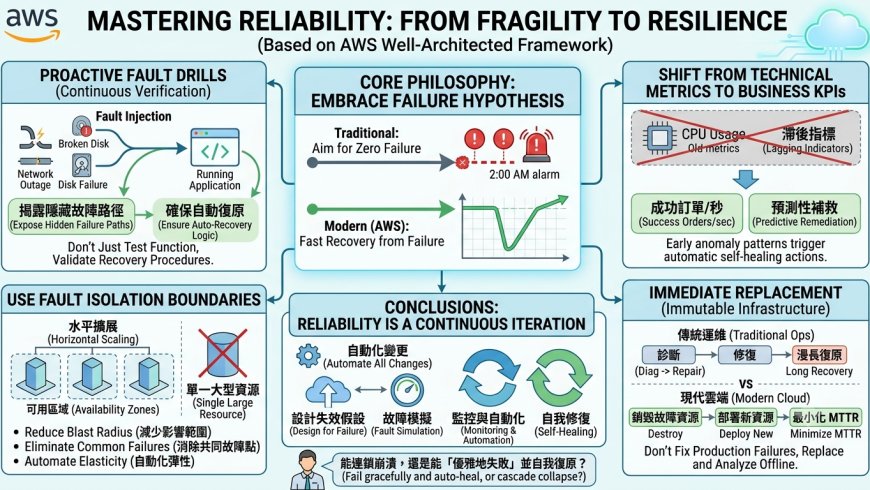
想像一下:凌晨兩點,你被公司的值班手機的急促告警訊息驚醒。螢幕上滿是紅色的連線逾時(Timeout)與資料庫負載爆表的訊息,核心服務正陷入全面崩潰。對於大多數技術主管或企業老闆來說,這是一場營運噩夢。
但在資深架構師的眼中,可靠性(Reliability)從來不是為了追求完美的「零失誤」,而是關於「如何快速從失誤中恢復」。在 AWS 的 Well-Architected 框架中,可靠性支柱的核心在於建立一套「失效假設」(Failure Hypothesis):我們預設所有組件最終都會失敗,並以此為基礎設計系統。這種思維轉向,是從「脆弱性」邁向「韌性」的關鍵第一步。
別只測功能,你該主動「演練故障」
在傳統地端環境中,測試的邏輯通常是驗證「系統在特定場景下是否有效」。但資深架構師知道,這種靜態思維無法應對雲端分散式系統的複雜性。真正的韌性來自於對「復原程序」的持續驗證,而非單純的功能測試。
在雲端環境,我們應導入「故障注入」(Fault Injection)的概念,主動模擬網路中斷、磁碟損毀或服務崩潰。這種做法能揭露隱藏的故障路徑,確保當災難真正降臨時,自動化的復原邏輯能如期啟動。
「在地端環境中,通常會進行測試以證明工作負載在特定場景下有效。測試通常不用於驗證復原策略。」
指標的迷思:從技術指標轉向「預測性補救」
許多工程師習慣盯著 CPU 使用率或記憶體負載,但這些「技術指標」往往滯後於用戶體感。在架構可靠系統時,KPI必須與「業務價值」掛鉤——例如:每秒處理的成功訂單數或 API 的成功回傳率。
更進一步,資深架構師會利用監控資料進行「預測性補救」(Predictive Remediation)。透過更複雜的自動化機制,我們能在指標尚未突破嚴重閾值前,就先識別出異常模式並啟動補救,在故障真正發生前消弭風險。
告別容量猜測:利用「故障隔離邊界」進行擴展
地端系統失效的主因常是「資源飽和」,這也是 DoS 攻擊最容易得手的地方。雲端架構讓我們能停止「猜測容量」,但單純的增加資源並不夠,必須結合「故障隔離邊界」(Fault Isolation Boundaries)。
可靠的系統應優先採取「水平擴展」(Horizontal Scaling),以多個小資源取代單一大型資源。其核心優勢在於:
- 減少影響範圍: 單一實例(Instance)故障僅會損失極小部分的處理能力,不會導致系統全滅。
- 消除共同故障點: 透過將資源分佈在不同的可用區域(Availability Zones, AZs),確保電力或網路等基礎設施故障時,系統仍具備存續能力。
- 自動化彈性: 監控實際利用率,在滿足需求的同時,避免過度配置帶來的成本浪費。
不修復,只替換:擁抱「不可變基礎架構」
這是一個關鍵的策略轉變。當生產環境中的資源發生故障,傳統運維習慣「登入系統、診斷、修復」。但在現代雲端架構中,我們倡導「不可變基礎架構」(Immutable Infrastructure):不再嘗試診斷受損資源,而是直接將其銷毀並替換。
「無需嘗試診斷和修復生產環境中的故障資源,而是可以用新的資源取代它,並對故障資源進行運作外的分析。」
這種做法能將**平均復原時間(MTTR)**壓縮至極致。工程師可以在不影響線上業務的前提下,在隔離環境中對故障資源進行冷靜的根因分析(RCA),從而真正提升系統穩定性。
自動化變更:將 RTO/RPO 內化為架構基因
人為操作是系統穩定性最大的變數。為了剔除人為錯誤,所有的基礎架構變更(從修補程式到功能更新)都必須透過自動化管理。
在設計之初,我們就必須將 **RTO(復原時間目標)與 作為設計架構的「濾鏡」。這不僅是為了速度,更是為了變更的「可追蹤性」與「審核歷史」。此外,不可忽視基礎設置(Foundations)**的重要性:
- 服務配額管理(Service Quotas): 防止意外的過度配置或 API 請求速率受限。
- 網路拓撲設計: 合理規劃 VPC、IP 位址與網域解析,避免基礎設施層級的崩潰。
結論:可靠性是一場持續的迭代賽
在 AWS 的實戰經驗告訴我們,可靠性不是一次性的部署成果,而是一個持續演進、不斷調整的循環。從「失效假設」出發,透過自動化、監控與頻繁的故障模擬,我們將「故障」從威脅轉化為系統優化的動力。
數位轉型的成敗,往往取決於當意外發生時,你的系統是會連鎖崩潰,還是能「優雅地失敗」並自動療癒。
最後,作為架構師,我想請你思考:如果明天你的核心服務突然消失,你的系統有能力在完全無人干預的情況下,完成自我復原嗎?





