想像一下這個令所有企業心驚膽顫的場景:現在是中午12點,SRE/DevOps團隊剛按下生產環境的部署按鈕。幾分鐘後,監控指標開始瘋狂跳紅,客戶/使用者的投訴如排山倒海而來。你急於修復,卻發現團隊從未預演過回滾計畫,甚至連誰有權限執行緊急操作都搞不清楚。這種混亂並非個案,而是缺乏維運框架的常態。
在 AWS 的世界裡,「卓越維運」的核心精神並非追求「永不犯錯」,而是學會如何「優雅地處理錯誤」。這不僅僅是技術問題,更是一種關於「人性」與「文化」的組織演進。本文將從《AWS 雲端架構框架—卓越維運篇》中,提煉出五個足以顛覆思維的實戰觀點,帶你重新定義維運的藝術。
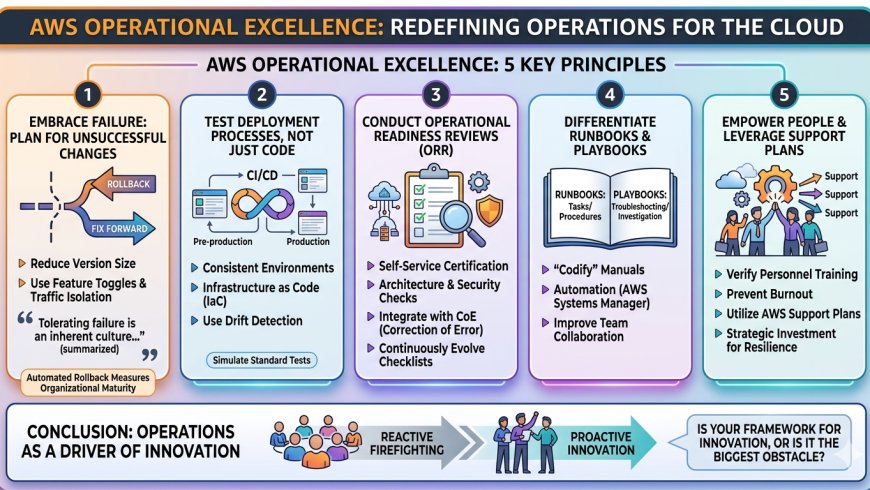
觀點一:擁抱失敗的勇氣——為「不成功的變更」進行規劃
在傳統觀念中,我們總是全神貫注於如何讓部署成功;然而,AWS卓越維運框架告訴我們,「規劃失敗」比規劃成功更為關鍵。為了將「爆炸半徑 (Blast Radius)」降至最低,架構師的首要任務是縮短版本規模 (Reducing version size)。
當變更導致不穩定時,團隊必須在「回滾 (Rollback)」與「向前修復 (Fix forward)」之間果斷決策。卓越的組織會預先制定策略,利用功能開關 (Feature Toggles) 與流量隔離技術,確保系統能承受任何組件變更引發的故障。
「容忍失敗的精神是卓越企業特有的文化,而且是高層直接給予的教誨。捍衛者必須不斷嘗試,並忍受隨之而來的失敗打擊,否則組織便無法從中學習。」——《追求卓越:探索成功企業的特質》
反思點: 自動化回滾不僅是縮短平均恢復時間 (MTTR) 的工具,它更是衡量組織成熟度的重要指標。敢於自動化回滾,代表你對系統監控具備極高的掌握度,能精準識別「不成功」的臨界點。
觀點二:不只是測試程式碼,更要「測試部署流程」
一個常見的維運反模式是:團隊投入大量精力測試程式邏輯,卻從未測試「部署到生產環境的腳步」。不一致性是生產環境穩定性的隱形殺手。
框架強調,「預生產 (Pre-production) 環境」必須在配置、安全控制與流程上與生產環境高度一致。基礎架構即代碼 (IaC) 不只是為了方便,它是達成這種一致性的唯一路徑。
實戰分析: 以一家線上電商公司為例,他們在 CI/CD 流水線中加入了「飄移偵測 (Drift Detection)」。這能精準捕捉那些繞過管道、私自手動修改的「熱修復 (Hotfixes)」。透過在類似生產環境中驗證 IaC 腳本,並確保服務能正確回應健康檢查,他們將維運支援的壓力降至最低。記住,零部署失敗的基礎,建立在無數次標準化的模擬測試之上。
觀點三:運作準備審查 (ORR)——系統上線前的「駕照考試」
系統在正式發布前,如何確保它已準備好面對現實世界的殘酷?AWS 提出了 ORR (Operational Readiness Reviews)。這不是官僚式的蓋章審核,而是一個源自 Amazon 數十年實戰經驗的「自助式認證」。
一份完整的 ORR 清單應包含:
- 架構建議: 是否符合雲端最佳實踐?
- 事件管理: 故障發生時的通報與處理流程是否明確?
- 發布品質: 是否具備測試數據與完整的復原計畫?
- 安全、治理與合規性: 維運卓越與安全性是不可分割的雙生子。
反思點: ORR 的生命力在於其「循環演進」。它必須與 CoE (Correction of Error) 流程深度整合。每一次的事後分析教訓,都應轉化為 ORR 的新項目,確保組織不會在同一個坑裡跌倒兩次。
觀點四:運行手冊 (Runbooks) vs. 行動手冊 (Playbooks)——你分得清楚嗎?
依賴工程師的「肌肉記憶」是維運的大忌,這會累積大量的「維運債務 (Operational Debt)」。卓越維運框架對此有明確定義:
- 運行手冊 (Runbooks): 用於執行特定程序的任務清單(如:更新資料庫架構)。目標是完成已知任務。
- 行動手冊 (Playbooks): 用於調查故障與事件處理的導引(如:診斷回應延遲)。目標是故障排除。
實戰分析: 資深架構師會推動手冊的「代碼化」。利用 AWS Systems Manager Automation 將文字轉化為自動化程序,或使用 Jupyter Notebooks 實現半自動化的互動式故障排除。此外,結合 AWS Systems Manager Incident Manager,能在跨團隊協作時確保資訊同步,消除溝通造成的延遲。
觀點五:人的因素——確保人員能力與支援計畫
再強大的技術,若缺乏合適的人才與支援機制,也難逃崩潰。人員能力直接影響維運風險,組織必須建立機制驗證受訓人員數量,並透過輪班與休假計畫防止倦怠。
此外,AWS Support 支援計畫應被視為維運戰略的一環,而非單純的技術客服。它是你的「回應時間保險」:
- Enterprise Support: 提供最快的回應時間,這在生產環境斷線時價值連城。
- Personal Health Dashboard (PHD): 主動監控與系統相關的 AWS 服務狀態。
- Trusted Advisor: 提供效能優化與成本節省的主動建議。
反思點: 在 24/7 運行的雲端時代,投資培訓與高階支援計畫並非額外成本,而是確保系統韌性的隱形投資。與供應商建立緊密的支援機制,是防止團隊在深夜孤軍奮戰的最佳防線。
結語:卓越維運並非終點,而是持續改進的路徑
卓越維運不是一個可以被勾選完成的項目,而是一個永無止境的演化過程。透過縮短版本規模、落實漂移偵測、強化 ORR、自動化手冊以及投資人才支援,我們能將維運從「被動救火」轉變為「主動創新」。
最後,請引導你的團隊思考一個發人深省的問題:
「如果明天你的系統發生了未曾預見的重大故障,你的團隊是會陷入指責與混亂,還是會慶幸自己早已有了一套優雅處理失敗的框架?」
你的維運流程,究竟是讓你更有信心去創新,還是成為了創新的最大阻礙?





